퍼셉트론(Perceptron)
다음은 입력 $x_1, x_2$ 에 대해 $y$ 를 출력하는 퍼셉트론입니다.
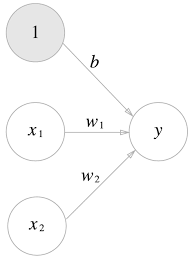
이와 같은 신경망을 학습하는 것은 입력으로 받는 $x_1, x_2$ 에 대해 적절한 가중치(weight) $w_1, w_2$ 와 편향(bias) $b$ 을 구하는 것이라고 할 수 있으며 이러한 가중치와 편향을 신경망에서는 파라미터(parameter)라고 합니다.
활성화 함수(Activation Function)
다음은 퍼셉트론의 동작을 나타냅니다.
$
y=
\begin{cases} 0 \ ( \, b + w_1 x_1 + w_2 x_2 \le 0 \ ) \\\\
1 \ ( \, b + w_1 x_1 + w_2 x_2 > 0 \ )
\end{cases}
$
$b + w_1 x_1 + w_2 x_2$ 의 값에 임계값 0을 기준으로 0과 1을 분류하는 것인데 이 같은 임계값을 경계로 출력이 바뀌는 함수를 계단 함수(step function)이라고 합니다.
def step_function(x):
if x > 0:
return 1
else:
return 0
또한 계단 함수와 같이 입력 신호에 대해 출력 신호로 변환하는 함수를 활성화 함수(activation function)라고 합니다. 보통 신경망에서는 활성화 함수로 비선형(nonlinear) 함수를 사용하는데, 이는 선형(linear) 함수를 사용하면 층을 깊게 하는 의미가 없기 때문입니다. 또한 활성화 함수로 사용하기 위해서는 미분 가능해야 하는데 이는 파라미터 업데이트 과정에서 미분을 이용하기 때문입니다.
데이터(Data)
학습의 목적은 주어진 데이터에 대해 적절한 파라미터를 구하는 것입니다. 그 과정에 있어 여러 데이터의 특성(feature)으로부터 패턴과 같은 규칙성을 찾아내고 파라미터를 조정하는 것입니다. 이 같은 데이터는 신경망 학습에서 없어서는 안되는 중요한 요소입니다.
다음은 Iris 라는 데이터의 구조입니다.
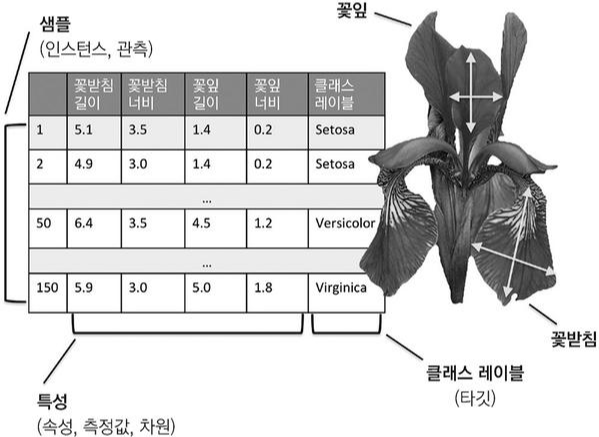
행은 샘플의 개수를 나타내며 열은 데이터가 갖는 특성을 의미합니다. 또한 해당 행에 대해 분류하고자하는 어떤 범주 또는 클래스의 값을 가지는 특성을 레이블(label)이라고 하며, 이 값은 신경망의 출력인 예측과 일치하고자하는 타겟(target)인 것입니다.
또한 데이터는 학습에 사용하는 학습 데이터(train data)와 테스트에 사용하는 테스트 데이터(test data)로 나누어지는데 이는 모델을 범용적으로 사용할 수 있게 일반화하는 것입니다.
다음과 같이 데이터가 분리되어 있지 않은 경우도 있습니다.
from sklearn.datasets import load_boston
boston = load_boston()
data = boston.data
target = boston.target
print(dir(boston))['DESCR', 'data', 'feature_names', 'filename', 'target']
사이킷런에서 제공하는 train_test_split 을 이용하면 학습 데이터와 테스트 데이터를 나눌 수 있습니다.
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(data, target, test_size=0.2)
여기서 test_size=0.2 의 의미는 데이터의 20% 를 테스트 데이터로 분리하는 것이며 기본적으로 무작위로 섞여서 분리됩니다.
손실 함수(Loss Function)
신경망 학습을 위한 방향 또는 성능 지표를 의미하며 이를 통해 신경망의 파라미터를 조정하는 것입니다. 이 같은 손실 함수는 예측의 목표가 되는 타겟과의 관계로 정의할 수 있습니다.
회귀 문제에서 주로 사용되는 손실 함수인 평균 제곱 오차(mean squared error, MSE)는 다음과 같습니다.
$MSE={1 \over n}\displaystyle \sum_{i=1}^n (y_i-\hat y_i)^2$
데이터 $n$ 개에 대해 타겟 $y$ 과 예측 $\hat y$ 의 오차(error) 또는 손실(loss)의 평균을 나타내는 것으로 예측이 타겟에 가까울수록 손실값은 0에 가까워지게 됩니다.
이러한 손실 함수는 신경망의 파라미터에 대해 미분이 가능해야 하며 이를 지표로 파라미터를 업데이트할 수 있게 됩니다.
경사 하강법(Gradient Descent)
경사 하강법은 파라미터를 학습하기 위한 최적화 알고리즘(optimizer)으로 손실 함수에서 계산된 손실값을 최소화(minimize)하는 방향으로 파라미터를 업데이트합니다.
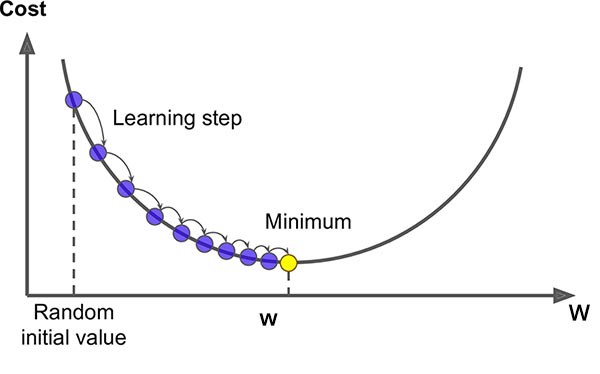
손실 함수의 최솟값을 구하기 위해서는 기울기(gradient)를 따라 손실값이 감소하는 방향으로 이동해야 하는데, 위와 같이 기울기가 음수인 지점이라면 $w$ 값이 커져야 손실값이 작아지게 되고 기울기가 양수라면 $w$ 값이 작아져야 손실값이 작아져 최종적으로 최솟값에 수렴하게 되는 것입니다.
이러한 기울기는 경사 하강법에서 손실값을 낮추는 방안을 제시하는 지표로서 이용되는 것이며 신경망의 파라미터인 가중치나 편향에 대한 손실 함수의 미분으로 구할 수 있습니다.
파라미터에 대한 평균 제곱 오차 손실 함수의 기울기는 다음과 같습니다.
$MSE={1 \over n}\displaystyle \sum_{i=1}^n (y_i-\hat y_i)^2$
${\partial \over \partial w} MSE(w, b)$
${\partial \over \partial b} MSE(w, b)$
또한 신경망의 파라미터는 벡터이며 각 파라미터가 손실값에 미치는 영향력을 알아내기 위해 편미분을 이용하는데 이는 대상 변수 외에 다른 변수는 상수로 취급하는 것을 의미합니다.
신경망의 파라미터를 업데이트하는 경사 하강법의 수식은 다음과 같습니다.
$\theta= \theta - \eta \, \nabla_\theta L(\theta)$
파라미터 $\theta$ 에 대한 손실 함수 $L(\theta)$ 의 기울기를 이용하여 파라미터를 업데이트하는 것으로 $\eta$ 는 학습률(step size, learning rate)로 업데이트하는 양을 의미합니다. 이러한 학습률은 하이퍼파라미터(hyperparameter)로 적절한 크기로 설정해야 안정적인 학습이 가능합니다.
신경망의 학습은 이러한 경사 하강법을 이용하여 반복적으로 파라미터를 업데이트하여 최적화(optimization)하는 것입니다.
추가적으로 배치(batch)와 관련하여 경사 하강법 종류는 다음과 같습니다.
- 확률적 경사 하강법(stochastic gradient descent, SGD)
- 배치 경사 하강법(batch gradient descent)
- 미니배치 경사 하강법(minibatch gradient descent)
배치란 경사 하강법의 계산에 사용되는 데이터의 단위를 의미합니다. 예를 들어 배치의 크기가 32이면 한 번에 계산되는 데이터의 개수가 32개라는 것입니다. 배치의 크기는 학습에 영향을 미치는 요소로 이와 관련하여 경사 하강법의 종류가 나뉘어 진 것입니다.
확률적 경사 하강법은 하나의 데이터(배치 크기 1)마다 계산하는 것으로 학습 전에 데이터를 무작위로 추출하기 때문에 확률적인 것입니다. 특징은 계산 비용이 적은 대신 수렴이 불안정합니다. 이에 반해 배치 경사 하강법은 모든 학습 데이터에 대해 한 번에 계산하는 것입니다. 특징은 계산 비용이 큰 대신 수렴 과정이 안정적입니다. 또한 두 방식을 절충한 것이 미니 배치 경사 하강법입니다.
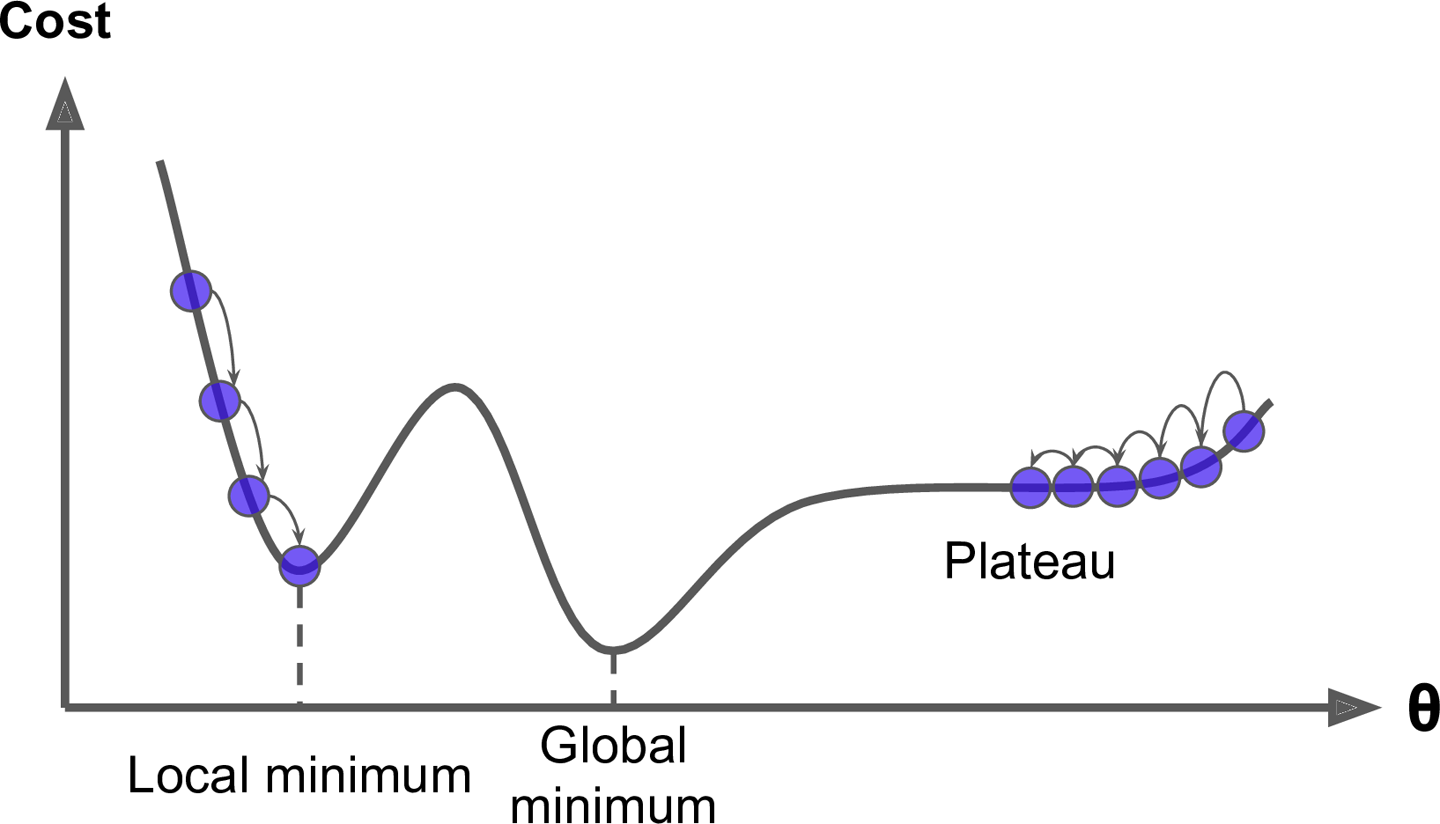
또한 경사 하강법에는 단점이 있는데 신경망 파라미터의 무작위 초기화(random initialization) 방식으로 인해 전역 극소값(global minimum)이 아닌 지역 극소값(local minimum)에 수렴할 수 있다는 것입니다.
구현
경사 하강법을 이용해 학습하는 선형 회귀 모델을 구현합니다.
학습 데이터를 생성합니다.
import numpy as np
import matplotlib.pyplot as plt
n = 50
x_data = np.random.rand(n, 1)
b_noise = np.random.normal(0, 0.5, size=(n, 1))
w = 5
b = 1
y_data = w * x_data + b + b_noise
plt.scatter(x_data, y_data)
plt.show()
모델을 정의합니다.
class Model:
def __init__(self, lr=0.01, epochs=100):
self.w = np.random.rand()
self.b = np.random.rand()
self.lr = lr
self.epochs = epochs
def predict(self, x):
return self.w * x + self.b
def train(self, x_data, y_data):
for epoch in range(self.epochs):
for x, y in zip(x_data, y_data):
y_hat = self.predict(x)
err = -(y - y_hat)
w_grad = self.lr * err * x
b_grad = self.lr * err
self.w -= w_grad
self.b -= b_grad
def draw_graph(self, x_data, y_data):
plt.scatter(x_data, y_data)
pt1 = (0.01, self.predict(0.01))
pt2 = (0.99, self.predict(0.99))
plt.plot([pt1[0], pt2[0]], [pt1[1], pt2[1]], 'red')
plt.title('Linear Regression')
plt.xlabel('x')
plt.ylabel('y')
plt.show()
학습을 수행합니다.
def train(self, x_data, y_data):
for epoch in range(self.epochs):
for x, y in zip(x_data, y_data):
y_hat = self.predict(x)
err = -(y - y_hat)
w_grad = self.lr * err * x
b_grad = self.lr * err
self.w -= w_grad
self.b -= b_grad
선형 회귀의 예측 $\hat y$ 을 수식으로 나타내면 다음과 같습니다.
$\hat y = wx + b$
1개의 데이터로 업데이트를 수행하여 손실 함수는 제곱 오차(squared error)를 이용합니다.
$L = {1 \over 2}(y - \hat y)^2$
가중치 $w$ 에 대한 손실 함수 $L$ 의 기울기는 다음과 같이 구할 수 있습니다.
$\begin{aligned}
{\partial L \over \partial w} & = {\partial \over \partial w} {1 \over 2}(y - \hat y)^2 \\
& = 2 * {1 \over 2}(y - \hat y) * - {\partial \over \partial w} \hat y \\
& = (y - \hat y) * -x \\
& = -(y - \hat y) x
\end{aligned}$
경사 하강법을 통한 파라미터 업데이트 식으로 나타내면 다음과 같습니다.
$\begin{aligned}
w & = w - \eta {\partial L \over \partial w} \\
& = w + \eta (y - \hat y) x
\end{aligned}$
학습을 진행하고 그래프를 확인합니다.
model = Model()
model.train(x_data, y_data)
model.draw_graph(x_data, y_data)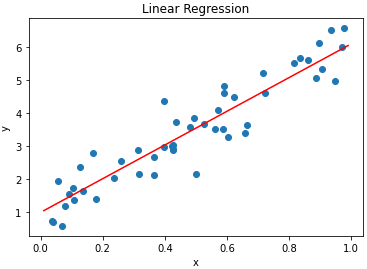
'머신러닝 > 딥러닝' 카테고리의 다른 글
| 교차 검증(Cross Validation) (0) | 2020.11.09 |
|---|---|
| 로지스틱 회귀(Logistic Regression) (0) | 2020.11.06 |
| 선형 회귀(Linear Regression) (0) | 2020.11.06 |
| 순전파와 역전파 (0) | 2020.11.06 |
| 퍼셉트론(Perceptron) (0) | 2020.11.04 |