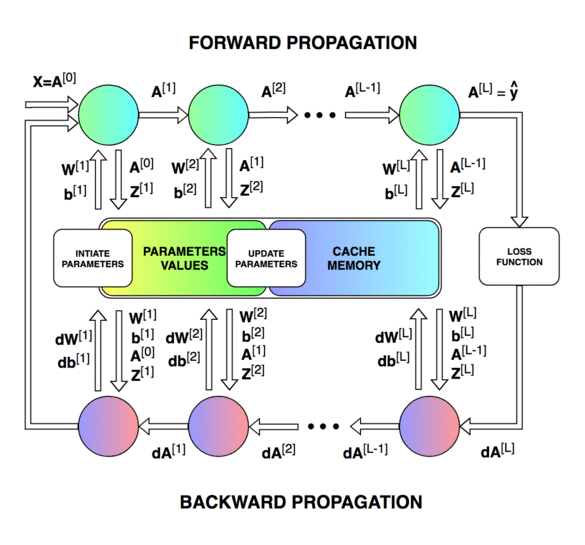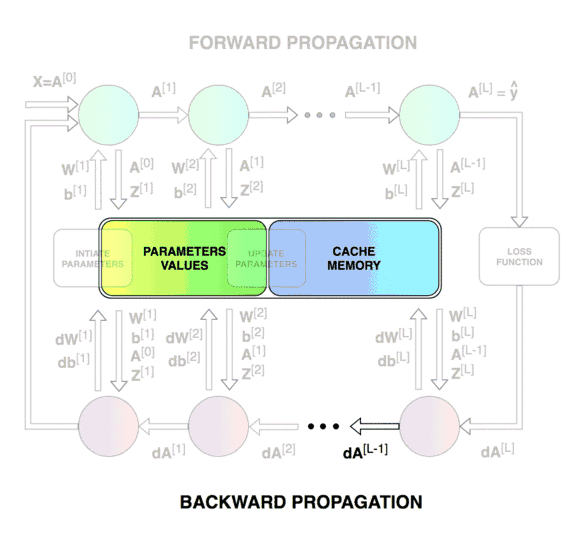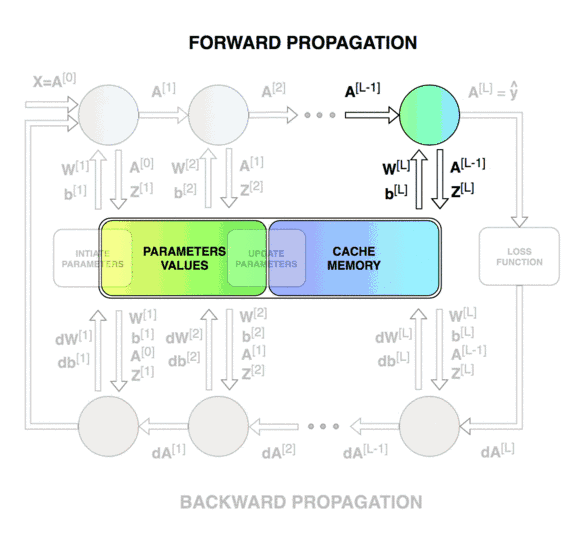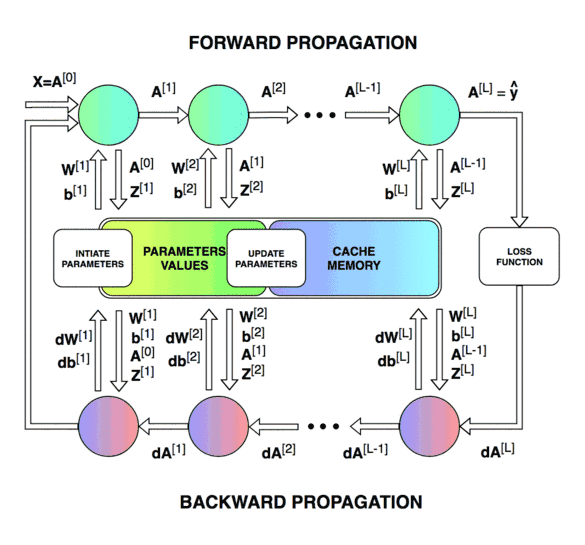
신경망(Neural Network) 신경망의 내부 동작은 추론 과정 에 해당하는 순전파(forward-propagation) 와 학습 과정 에 해당하는 역전파(back-propagation) 로 나누어집니다.
특히 역전파는 다층 퍼셉트론과 같은 은닉층(hidden layer)을 포함하는 신경망에서 경사 하강법(gradient descent) 을 이용한 학습 과정으로 미분의 체인 룰(chain rule) 을 통해 기울기가 역으로 전파되어 파라미터가 업데이트되는 원리입니다.
예제를 통해 순전파와 역전파의 계산 과정을 알아보겠습니다.
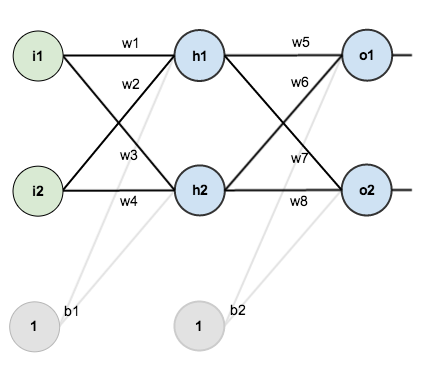
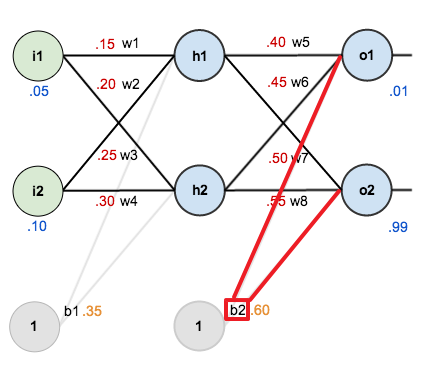
다음 신경망은 입력층, 은닉층, 출력층으로 구성되며 각 층은 2개의 노드를 가지고 있습니다.
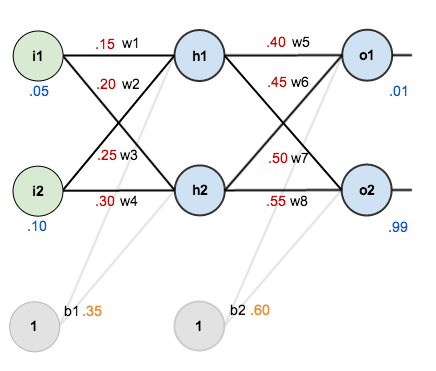
신경망에서 학습 가능한 파라미터는 가중치 $w_1$~$w_8$ 와 편향 $b_1, b_2$ 이며, 은닉층 노드 $h_1, h_2$ 와 출력층 노드 $o_1, o_2$ 에는 시그모이드 활성화 함수가 사용됩니다. 또한 손실 함수는 평균 제곱 오차를 사용하며 경사 하강법의 학습률은 0.5로 지정합니다.
초기 파라미터 값은 다음과 같습니다.
순전파(Forward-Propagation) 먼저 노드 $h_1$ 의 입력 $net_{h_1}$ 에 대해 계산합니다.
$ net_{h_1} = w_1 * i_1 + w_2 * i_2 + b_1 = 0.15 * 0.05 + 0.2 * 0.1 + 0.35 = 0.3775 $
$ net_{h_1} $ 을 시그모이드 함수를 통한 출력 $ out_{h_1} $ 은 다음과 같습니다.
$ out_{h_1} = {1 \over {1 + e^{net_{h_1}}} } = {1 \over {1 + e^{ -0.3775 }} } = 0.593269992 $
$ h_2 $ 도 같은 방식으로 계산합니다.
$ net_{h_2} = w_3 * i_1 + w_4 * i_2 + b_1 = 0.25 * 0.05 + 0.3 * 0.1 + 0.35 = 0.3925 $
$ out_{h_2} = {1 \over {1 + e^{net_{h_2}}} } = {1 \over {1 + e^{ -0.3925 }} } = 0.596884378 $
$ h_1, h_2 $ 에 대해 정리하면 다음과 같습니다.
$ net_{h_1} = 0.3775 $$ net_{h_2} = 0.3925 $
$ out_{h_1} = 0.593269992 $
$ out_{h_2} = 0.596884378 $
위와 같은 방식으로 노드 $ o_1, o_2 $ 를 계산합니다.
$\begin{aligned}
$ out_{o_1} = {1 \over {1 + e^{net_{o_1}}} } = {1 \over {1 + e^{ -1.1059059669 }} } = 0.7513650695224682 $
$\begin{aligned}
$o_1, o_2$ 에 대해 정리하면 다음과 같습니다.
$net_{o_1} = 1.1059059669$
신경망의 출력과 타겟의 평균 제곱 오차를 계산합니다. 계산에 편의를 위해 $ 1 \over 2 $ 를 곱하며 1개의 입력에 대한 것이므로 다음과 같이 나타낼 수 있습니다.
$E = { 1\over 2 } (y - \hat y)^2 $
출력 $out_{o_1}$ 에 대한 타겟값은 $0.01$ 이며, $out_{o_2}$ 에 대한 타겟값은 $0.99$ 입니다.
$ target_{o_1} = 0.01 $
$ target_{o_2} = 0.99 $
$ E_{o_1} = { 1 \over 2 } ( target_{o_1} - out_{o_1} )^2 = { 1 \over 2 } ( 0.01 - 0.7513650695224682 )^2 = 0.274811083 $
$ E_{o_2} = { 1 \over 2 } ( target_{o_2} - out_{o_2} )^2 = { 1 \over 2 } ( 0.99 - 0.772928465286981 )^2 = 0.023560026 $
오차의 합을 계산합니다.
$ E_\text{total} = E_{o_1} + E_{o_2} = 0.274811083 + 0.023560026 = 0.298371109 $
역전파(Back-Propagation) 신경망에서 학습 가능한 파라미터는 가중치 $w_1$~$w_8$ 와 편향 $b_1, b_2$ 입니다. 이에 대해 경사 하강법을 적용하기 위해서는 먼저 각 파라미터에 대해 기울기를 계산해야 합니다.
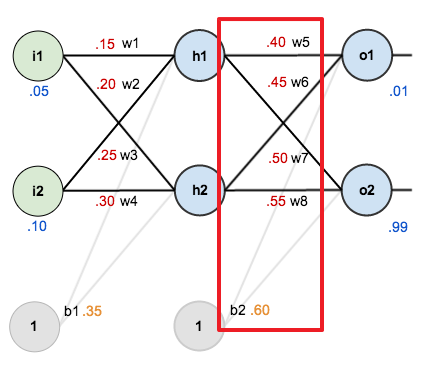
우선 출력층에 가까운 $w_5$~$w_8$, $b_2$ 에 대해 업데이트를 진행합니다.
$w_5$ 에 대한 오차의 기울기 $\partial E_\text{total} \over \partial w_5$ 는 체인 룰 에 의해 다음과 같이 나타낼 수 있습니다.
${\partial E_{total} \over \partial w_5} = {\partial E_\text{total} \over \partial out_{o_1}} {\partial out_{o_1} \over \partial net_{o_1}} {\partial net_{o_1} \over \partial w_5 }$
다음 항을 계산합니다.
${\partial E_\text{total} \over \partial w_5} = \color{red}{\partial E_\text{total} \over \partial out_{o_1}} {\partial out_{o_1} \over \partial net_{o_1}} {\partial net_{o_1} \over \partial w_5 }$
$\begin{aligned}
다음 항을 계산합니다.
${\partial E_\text{total} \over \partial w_5} = {\partial E_\text{total} \over \partial out_{o_1}} \color{red}{\partial out_{o_1} \over \partial net_{o_1}} {\partial net_{o_1} \over \partial w_5 }$
$ out_{o_1} $ 는 시그모이드 함수를 통한 출력입니다.
$ out_{o_1} = {1 \over { 1 + e^{-net_{o_1}} }} $
시그모이드 함수의 미분은 다음과 같습니다.
$ {\partial \over \partial x} \sigma (x) = \sigma (x) (1 - \sigma(x)) $
따라서 다음과 같이 계산할 수 있습니다.
$\begin{aligned}
다음 항을 계산합니다.
${\partial E_\text{total} \over \partial w_5} = {\partial E_\text{total} \over \partial out_{o_1}} {\partial out_{o_1} \over \partial net_{o_1}} \color{red}{\partial net_{o_1} \over \partial w_5 }$
$\begin{aligned}
최종적으로 $ {\partial E_\text{total} \over \partial w_5} $ 은 다음과 같습니다.
$\begin{aligned}
이어서 경사 하강법을 적용하여 $w_5$ 를 업데이트합니다.
$\begin{aligned}
이렇게 오차가 역방향으로 전파되어 파라미터를 업데이트하는 과정이 바로 오차 역전파인 것입니다.
같은 방식으로 나머지 $w_6$ 을 업데이트합니다.
$\begin{aligned}
$\begin{aligned}
$w_7, w_8$ 은 출력 노드 $o_2$ 에 영향을 주는 파라미터입니다.
${\partial E_\text{total} \over \partial w_7} = {\partial E_\text{total} \over \partial out_{o_2}} {\partial out_{o_2} \over \partial net_{o_2}} {\partial net_{o_2} \over \partial w_7 }$
$\begin{aligned}
$\begin{aligned}
$\begin{aligned}
$\begin{aligned}
$\begin{aligned}
$\begin{aligned}
$\begin{aligned}
편향 $b_2$ 은 2개의 출력 노드 $o_1, o_2$ 에 영향을 주는 파라미터입니다.
따라서 $b_2$ 에 대한 전체 오차 $E_\text{total}$ 의 미분을 다음과 같이 나타낼 수 있습니다.
${ \partial E_\text{total} \over \partial b_2} = { \partial E_{o_1} \over \partial b_2} + { \partial E_{o_2} \over \partial b_2}$
각각 체인 룰을 적용합니다.
$\begin{aligned}
$\begin{aligned}
$\begin{aligned}
경사 하강법을 적용해 $b_2$ 를 업데이트합니다.
$\begin{aligned}
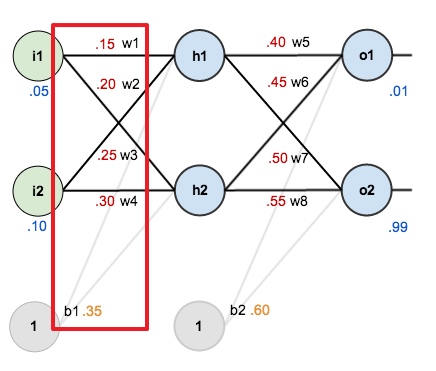
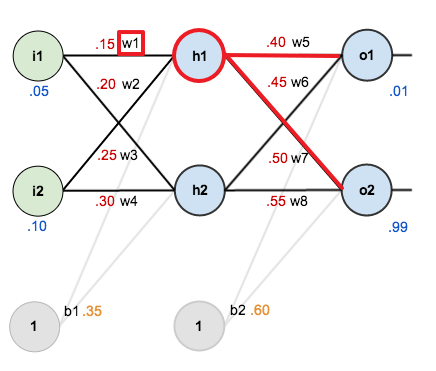
다음은 $w_1$~$w_4$, $b_1$ 에 대한 업데이트입니다.
$w_1$ 에 대한 기울기는 다음과 같이 나타낼 수 있습니다.
$ { \partial E_\text{total} \over \partial w_1 } = { \partial E_\text{total} \over \partial out_{h1} } { \partial out_{h_1} \over \partial net_{h_1} } { \partial net_{h_1} \over \partial w_1 } $
여기서 은닉층의 노드 $h_1$ 의 출력 $out_{h_1}$ 은 2개의 출력 노드 $o_1, o_2$ 에 영향을 줍니다.
따라서 다음과 같이 나누어 줄 수 있습니다.
$ { \partial E_\text{total} \over \partial w_1 } = \color{red}{ \partial E_\text{total} \over \partial out_{h1} } { \partial out_{h_1} \over \partial net_{h_1} } { \partial net_{h_1} \over \partial w_1 } $
${ \partial E_\text{total} \over \partial out_{h_1} } = { \partial E_{o_1} \over \partial out_{h_1} } + { \partial E_{o_2} \over \partial out_{h_1} }$
각각 체인 룰을 적용하면 다음과 같습니다.
${ \partial E_{o_1} \over \partial out_{h1} } = { \partial E_{o_1} \over \partial out_{o_1} } { \partial out_{o_1} \over \partial net_{o_1} } { \partial net_{o_1} \over \partial out_{h_1} } $
${ \partial E_{o_2} \over \partial out_{h_1} } = { \partial E_{o_2} \over \partial out_{o_2} } { \partial out_{o_2} \over \partial net_{o_2} } { \partial net_{o_2} \over \partial out_{h_1} } $
위에서 계산한 내용은 다음과 같습니다.
${\partial E_{o_1} \over \partial out_{o_1}} = 0.741365069$
${\partial out_{o_1} \over \partial net_{o_1}} = 0.186815602$
${\partial E_{o_2} \over \partial out_{o_2}} = -0.217071535$
${\partial out_{o_2} \over \partial net_{o_2}} = 0.175510053$
다음 항을 계산합니다.
${ \partial E_{o_1} \over \partial out_{h_1} } = { \partial E_{o_1} \over \partial out_{o_1} } { \partial out_{o_1} \over \partial net_{o_1} } \color{red}{ \partial net_{o_1} \over \partial out_{h_1} } $
$ { \partial net_{o_1} \over \partial out_{h_1} } = {\partial \over \partial out_{h_1}} (w_5 * out_{h_1} + w_6 * out_{h_2} + b_2) = w_5 = 0.4 $
$ { \partial E_{o_1} \over \partial out_{h_1} } $ 을 계산합니다.
$\begin{aligned}
동일한 방식으로 ${ \partial E_{o_2} \over \partial out_{h_1} }$ 도 계산합니다.
$\begin{aligned}
최종적으로 ${ \partial E_\text{total} \over \partial out_{h_1} }$ 은 다음과 같습니다.
$\begin{aligned}
다음 항을 계산합니다.
$ { \partial E_\text{total} \over \partial w_1 } = { \partial E_\text{total} \over \partial out_{h1} } \color{red}{ \partial out_{h_1} \over \partial net_{h_1} } { \partial net_{h_1} \over \partial w_1 } $
$ { \partial out_{h_1} \over \partial net_{h_1} } = out_{h_1} ( 1 - out_{h_1} ) = 0.593269992 ( 1 - 0.593269992 ) = 0.241300709 $
다음 항을 계산합니다.
$ { \partial E_\text{total} \over \partial w_1 } = { \partial E_\text{total} \over \partial out_{h1} } { \partial out_{h_1} \over \partial net_{h_1} } \color{red}{ \partial net_{h_1} \over \partial w_1 } $
$ { \partial net_{h_1} \over \partial w_1 } = { \partial \over \partial w_1 } ( w_1 * i_1 + w_2 * i_2 + b_1 ) = i_1 = 0.05 $
최종적으로 $ { \partial E_\text{total} \over \partial w_1 } $ 을 계산합니다.
$\begin{aligned}
경사 하강법을 적용하여 $w_1$ 을 업데이트합니다.
$\begin{aligned}
동일하게 가중치 $w_2, w_3, w_4$ 도 업데이트합니다.
$\begin{aligned}
$\begin{aligned}
$\begin{aligned}
$\begin{aligned}
$\begin{aligned}
$\begin{aligned}
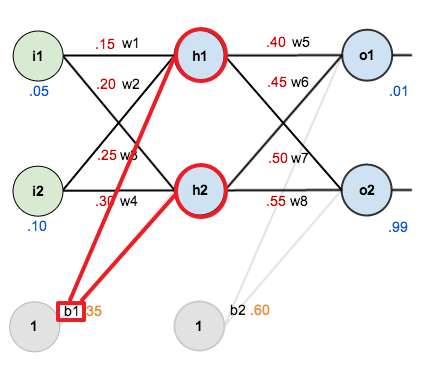
편향 $b_1$ 은 2개의 은닉층 노드 $h1, h2$ 에 영향을 주는 파라미터입니다.
따라서 $b_1$ 에 대한 기울기는 다음과 같이 구할 수 있습니다.
$\begin{aligned}
$\begin{aligned}
여기까지 모든 파라미터에 대한 업데이트를 완료했습니다.
$\begin{aligned}
이제 업데이트된 파라미터를 이용해 다시 순전파를 통해 출력값을 계산합니다.
$\begin{aligned}
$ out_{h_1} = {1 \over {1 + e^{net_{h_1}}} } = {1 \over {1 + e^{ -0.372415138 }} } = 0.592042432$
$\begin{aligned}
$ out_{h_2} = {1 \over {1 + e^{net_{h_2}}} } = {1 \over {1 + e^{ -0.3874077449 }} } = 0.595658511 $
$\begin{aligned}
$ out_{o_1} = {1 \over {1 + e^{net_{o_1}}} } = {1 \over {1 + e^{ -1.005719116 }} } = 0.732181538 $
$ \begin{aligned}
$ out_{o_2} = {1 \over {1 + e^{net_{o_2}}} } = {1 \over {1 + e^{ -1.186896776 }} } = 0.766185596 $
$ E_{o_1} = { 1 \over 2 } ( target_{o_1} - out_{o_1} )^2 = { 1 \over 2 } ( 0.01 - 0.732181538 )^2 = 0.260773087$
$ E_{o_2} = { 1 \over 2 } ( target_{o_2} - out_{o_2} )^2 = { 1 \over 2 } ( 0.99 - 0.766185596 )^2 = 0.025046444$
$ E_\text{total} = E_{o_1} + E_{o_2} = 0.260773087 + 0.025046444 = 0.285819531 $
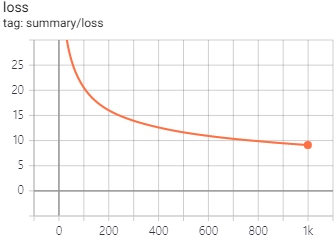
기존 오차와 비교해 감소되었습니다.
$ E_\text{old total} - E_\text{new total} = 0.298371109 - 0.285819531 = 0.012551578$